
Oğlum bir yaşını doldurduktan sonra doktorumuzun o meşhur tavsiyesiyle tanıştık: “Onunla sürekli konuşun, ne anlattığınızın hiçbir önemi yok, sadece konuşun!” Hal böyle olunca benim akşamları “car car” mesaim de resmen başlamış oldu. Ama bunu fırsata dönüştürüp en azından teknik çalışmaları veya yazılım ile alakalı şeyler okursam hem konuşmuş olur hem deüç-beş bilgi öğrenirim diye düşündüm ve Github üzerinde çalışmalar hakkında sürekli yazılar okuyordum. Böyle günlerden birinde masal niyetine system-design-primer mimarisini anlatırken aklıma bir senaryo gelmişti.
“Eğer atom fiziğine lanet olsun diyerek işinden istifa eden bir beyaz yakalı Ege sahillerinde küçük bir kafe açmak yerine bir sosyal medya uygulaması yapmak istese ne kadar para harcar?”
Hemen Quora ve Reddit gibi yazıları okuduğumda kafayı yer gibi oldum. Meta, yapay zeka dışındaki teknoloji yatırımları 2027 sonunda 125 milyar $ seviyesini hedeflerken X gibi görece daha az harcama yapan sosyal medya devi ise xAI dışındaki teknoloji yatırımları aylık 550 milyon $ seviyelerindeydi.
Hemen orada oğluma dönüp şu challenge’ı başlattım:
- Eğer cebimizdeki para sadece yazılımcı maaşına ve reklama yetiyorsa; herhangi bir pahalı tool, managed cloud servisi veya lisans ücreti kullanmadan, sadece mimari değişikliği ile bu maliyetleri en dibe nasıl çekeriz?
Senaryomuz bu olacaktı. Herhangi bir cloud, scale tool, lisanslama ücretleri olmadan sadece mimari farklar ile bu işi kotarmaya çalışmak. Doğru ya da yanlış düşündüğüm şeylerin hepsini oğluma da anlatmaya başladım ve ona anlattıklarımı da sizlere de anlatmak için bu yazıyı yazdım :) Şimdiden iyi okumalar.
Giriş: 550 milyon $ Milyon Dolarımız Olmadığında Ne Yapıyoruz?
Öncelikle belirtmek isterim burada yazan yazı profesyonel şirketler için uygulanabilir olmayabilir veya en ideal sistem değildir. Amacımız bir fikir deneyi yapmak ve mühendisliği en temel işlemi olan minimum bütçe - maksimum verim yakalamaya çalışmak. Bu işin en makul ve ideal yöntemleri zaten bir çok yerde yazılmış. Biz ise bir kaç tool ve cloud kullanmadan sadece mimari farkları ile fiyat ne kadar düşebilir diye düşünmek ve buradaki trade-off ları hesaplamak. O yüzden bugün, “parayı donanıma gömmek” yerine “zekayı mimariye gömmek” üzerine bir düşünce deneyi yapacağız.
Eğer system-design-primer reposundaki o meşhur Twitter mimarisini harfi harfine kopyalayıp AWS üzerine kurmaya kalksaydık, sadece cloud altyapı için ayda yaklaşık 7.73 milyon doları (evet, yanlış duymadın!) masaya bırakmamız gerekirdi. Bunun yanında database, ssl, tech-stack lisansları, donanım ve enerji maliyetleri, sharding bütçeleri, cdn maliyetleri gibi ücretler ile bu rakam 550 milyon $ olabiliyor. Ama bizim bütçemiz kısıtlı, cebimiz delik ve saniyede 1 milyon kullanıcı kapıya dayanmak üzere.
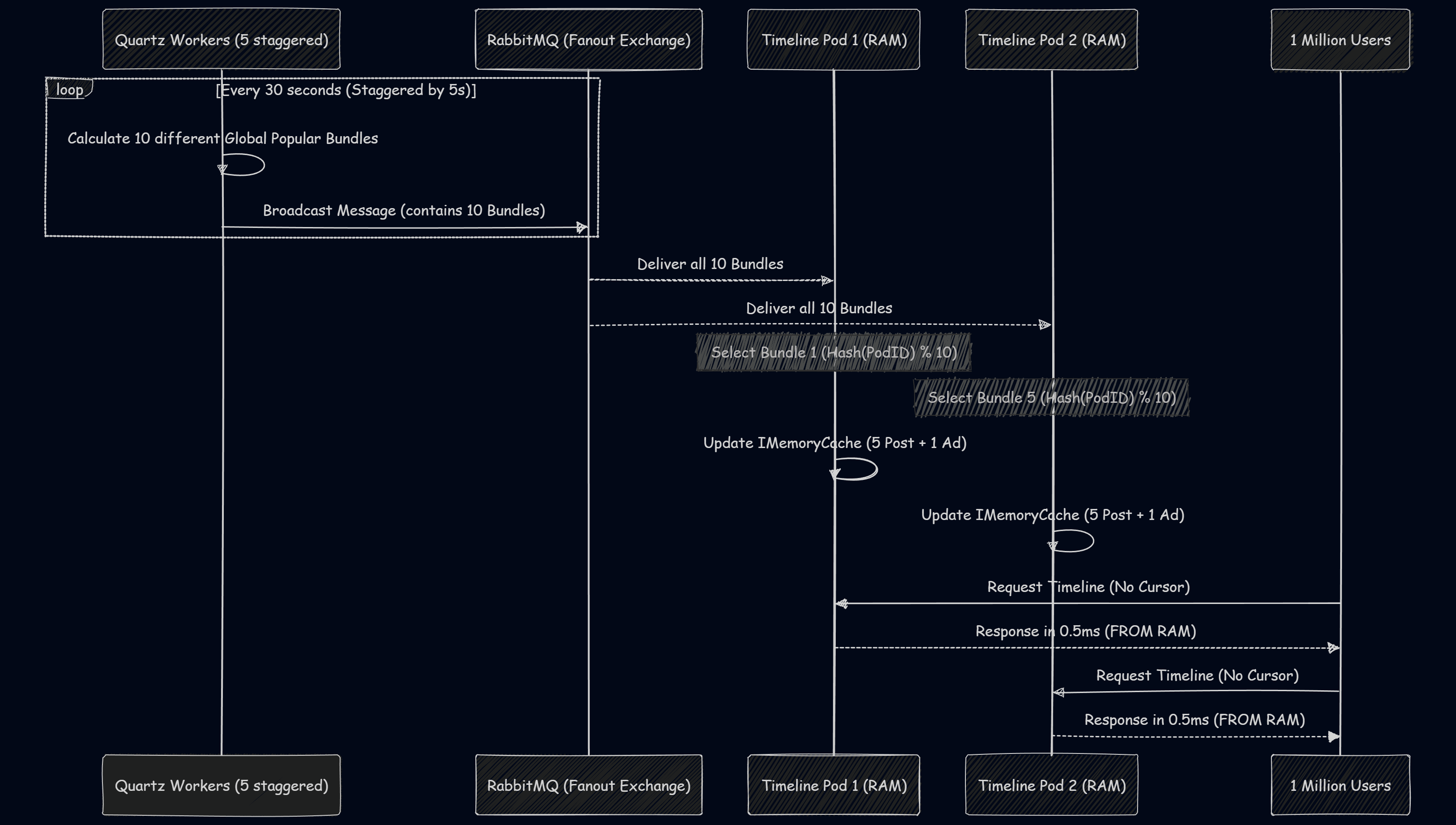
1. Savunma Hattı: Quartz & RabbitMQ ile “Yankı Odası” Mekanizması
Bu hat, sistemimizin “fedai” katmanıdır. Amacımız, 1 milyon kullanıcının %80’ini daha veritabanının kapısına bile yaklaştırmadan, Pod’ların yerel RAM’inde (L1 Cache) durdurmak. Ama bunu yaparken hepsine aynı yemeği yedirip “sıkıcı” görünmek istemiyoruz. İşte burada staggered job ve pod bundling devreye giriyor.
Teknik Kurgu: 5 İşçi, 5 Saniye, 10 Dünya
- Staggered Quartz Jobs: 5 farklı Quartz job’ımız var. Aralarında 5’er saniye farkla tetikleniyorlar. Yani her an bir yerlerde taze data hesaplanıyor. Her işçi, o anki veritabanı durumuna göre “farklı” bir popülerlik seti (5 post + 1 reklam) çıkarıyor.
- Broadcast & Seçim: Bu 5 işçi, buldukları paketleri RabbitMQ’nun Fanout Exchange yapısına fırlatıyor. Exchange bu mesajı ayaktaki tüm Pod’lara (diyelim ki 100 tane) kopyalıyor.
- Pod Kimliği (The Unique Pod): Her Pod mesajı aldığında “Dur bakayım, bu paketin içinde 10 farklı bundle var, hangisi benim?” diyor. Pod, kendi
HostnameveyaIPbilgisini hash’leyip (örneğinPodIndex % 10) kendine özel o 6 kaydı alıpIMemoryCache‘e yani RAM’e gömüyor.
Felsefi Trade-off: Suni Ünlülük ve Yankı Odası
Burada mühendislik etiği ile cüzdanımız arasında bir pazarlık yapıyoruz.
- Tez:
- Gerçek zamanlı, kişiselleştirilmiş timeline her zaman en iyisidir.
- Liveliness: Kullanıcı Pod-1’den Pod-2’ye sekse bile, farklı içerik görmesi platformu daha “canlı” ve “kalabalık” hissettirecek.
- Ad Delivery Guarantee: Reklamın yerel RAM’de olması, reklam verene “saniyede 1 milyon gösterim” garantisi vermemizi sağlıyor.
- Antitez: 1M RPS’i kişiselleştirmeye kalkarsan server masrafından dolayı çocukların rızkını cloud sağlayıcısına yedirirsin.
- Sentez (Yankı Odası): Biz kullanıcıyı pod bazlı bir odaya kapatıyoruz. Pod-1’e düşen 100 bin kişi, aslında o an dünyada en popüler olmayan ama bizim popüler olmasını istediğimiz 5 kişiyi görüyor. Bu 100 bin kişi aynı 5 postu beğendiğinde, o kişiler bir anda “organik” olarak ünlü olmaya başlıyor. Paranın gözü kör olsun; biz algoritmik bir kader tayin ediyoruz ama karşılığında sıfır veritabanı maliyeti alıyoruz!
2. Savunma Hattı: RAM Tabanlı 5+1 Post Mekanizması
Sisteme eş zamanlı giriş yapan 1 milyon kullanıcı, veritabanı katmanı için bir “dağıtık hizmet engelleme” (DDoS) etkisi yaratabilir. Bu kaosu önlemek adına geliştirilen ikinci savunma hattı, kullanıcıyı veritabanından tamamen izole eden RAM tabanlı bir ön yükleme stratejisidir. 1 Kullanıcı uygulamayı açtığı anda karşılaştığı ilk içerik seti, o anlık bir veritabanı sorgusunun sonucu değil, arka planda çalışan “job” (iş) katmanının önceden hazırlayıp RAM’e (L1/L2 önbellek) yazdığı statik-dinamik bir karmadır.
Arka Plan İşleri ve Bellek Yönetimi
Sistemin “soğuk başlangıç” (cold start) maliyetini sıfıra indirmek için kullanılan bu modelde, arka plan işleri (background jobs) sürekli olarak platformun en popüler, en çok etkileşim alan veya editöryal olarak öne çıkarılan içeriklerini tarar. Bu işler, her kullanıcı segmenti veya genel havuz için 5 adet standart içerik ve 1 adet sponsorlu/tanıtıcı içerikten (5+1) oluşan paketler hazırlar. Hazırlanan bu paketler, Redis gibi düşük gecikmeli bir L2 dağıtık önbellek sistemine veya uygulama sunucularının yerel belleğindeki (L1) Concurrent Dictionary gibi yapılara yazılır.
Bu yapının en büyük avantajı, ağ gecikmesini ve veritabanı üzerindeki giriş/çıkış (I/O) baskısını ortadan kaldırmasıdır. 1 milyon kullanıcının her biri için atılacak bir SELECT * FROM posts sorgusu, indeksli olsa bile disk I/O limitlerine takılacaktır; ancak RAM üzerindeki bir anahtar-değer (key-value) okuması mikrosaniye mertebesinde tamamlanır
| Performans Metriği | L1 Yerel Bellek (RAM) | L2 Dağıtık Bellek (Redis) | Veritabanı (Disk/SSD) |
|---|---|---|---|
| Erişim Gecikmesi | ~100 nanosaniye | ~1 milisaniye | 10 - 100 milisaniye |
| Maksimum Kapasite | Megabayt Mertebesi | Gigabayt Mertebesi | Terabayt/Sınırsız |
| Ölçeklenebilirlik | Sunucu Başına Bağımsız | Kümeleme (Clustering) ile Yüksek | Sharding ile Orta/Zor |
| Veri Tutarlılığı | En Düşük (Sunucu Bazlı) | Orta-Yüksek (Paylaşımlı) | En Yüksek (ACID) |
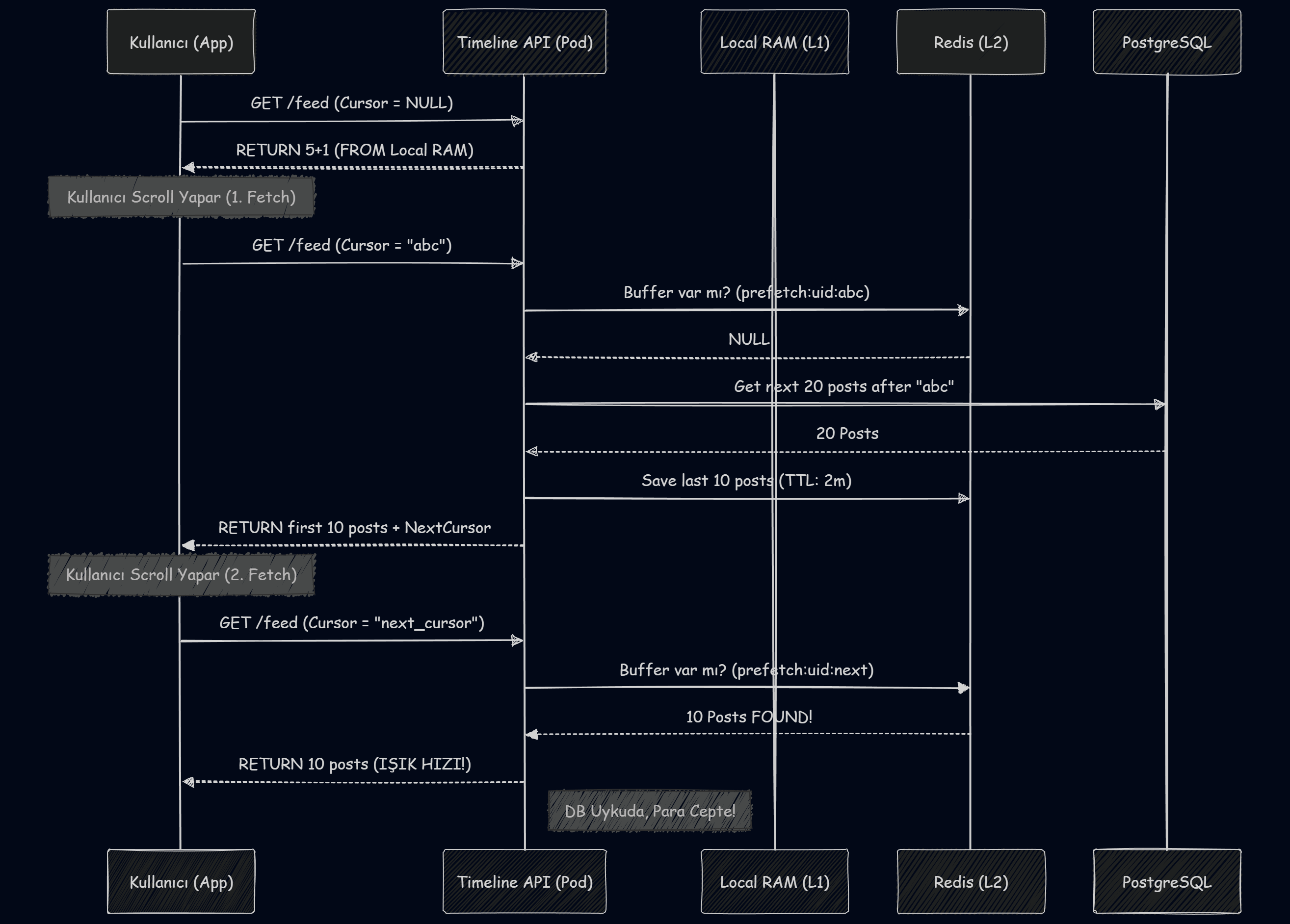
Kullanıcının ilk isteği sırasında sistem, istek içerisinde bir cursor veya page_index olup olmadığını kontrol eder. Eğer bu parametreler eksikse, sistem kullanıcının “yeni” olduğunu veya session başlattığını anlar ve doğrudan RAM’deki bu 6’lı paketi servis eder. Bu aşamada veritabanına hiçbir dokunuş yapılmaz; bu durum, sistemin 1 milyon RPS gibi devasa yükler altında bile ayakta kalmasını sağlayan temel sigortadır.
İnatçı Kesim: 10+10 Lookahead Pagination “Bir Alana Bir Bedava”
İlk 6 postu tüketen kullanıcıların yaklaşık %90’ı genellikle uygulamadan çıkar veya farklı bir sekmeden devam eder. Ancak, sistemin asıl teknik yükünü oluşturan “inatçı %10’luk kesim”, scroll (kaydırma) yapmaya devam ederek akışın derinliklerine iner. Bu kullanıcılar için sistemin artık daha dinamik ve kişiselleştirilmiş bir strateji izlemesi gerekir. İşte bu noktada “10+10 Lookahead Pagination” devreye girer. Öyle ya senaryomuzda 1 milyon kişi aynı anda feed apisine ulaşabilir ama aynı anda scroll yapar demiyor.
Buradaki hamlemiz şu: Madem bir kez veritabanına gidiyoruz (ki bu pahalı bir işlem), neden sadece 10 tane alalım?
- Adım: Veritabanından 20 kayıt çekiyoruz.
- Adım: İlk 10’unu kullanıcıya anında paketleyip gönderiyoruz.
- Adım: Kalan 10’unu Redis’e, kullanıcının
userId‘si ile ilişkili bir anahtara 2-5 dakikalık kısa bir TTL (ömür) ile “Yedek” olarak fırlatıyoruz. - Adım: Kullanıcı 3. kez scroll yaptığında veritabanına asla gitmiyoruz. Redis’teki o sıcak 10 kaydı veriyoruz. Bu sayede veritabanı “Round-trip” faturamız matematiksel olarak %50 düşüyor!.
Trade-offs
- Her inatçı kullanıcı için arka planda fazladan 10 postun (lookahead) hazır tutulması, RAM tüketimini %100 artırır. 1 milyon kullanıcının %10’u olan 100.000 kişi için, her postun 5KB olduğu varsayılırsa, fazladan gigabaytlarca RAM ihtiyacı doğar. Ancak bu maliyet, veritabanını dikey ölçekleme maliyetinden çok daha düşüktür.
- Cursor tabanlı sistemler, basit sayfa numaralarına göre çok daha zordur. Cursor’ların encode edilmesi, versiyonlanması (yazılım güncellendiğinde eski cursor’ların patlamaması) ve hata yönetimi ciddi bir mühendislik disiplini gerektirir.
Tez, Antitez ve Sentez: Pagination Diyalektiği
- Tez :
- “Sadece ihtiyacın olan 10 kaydı çek.” (DB’yi yorar, her scroll’da DB’ye kafa atarsın).
- Kısa vadeli tıklama oranları (CTR), beğeni ve paylaşım sayıları tavan yapar.
- Antitez: “Kullanıcının tüm timeline’ını Redis’e önceden yaz (Twitter’ın milyarlık yolu).”
- Sentez : “10+10 Lookahead Pagination.” Bir kez git 20 al, yarısını o an ver, yarısını kısa süreli sakla. Hem DB’yi %50 rahatlat hem de RAM’i sadece 2 dakika meşgul et.
3. Savunma Hattı: İlgi bağımlısı Influencer Gönderileri
Bir influencer’ın (örneğin 50 milyon takipçisi olan biri) gönderi paylaştığını düşünelim. Saf bir Push modelinde, sistem 50 milyon Redis anahtarını güncellemeye çalışacaktır. En hızlı Redis kümesi bile saniyede yüz binlerce operasyon yapabilirken, 50 milyonluk bir güncellemeyi tamamlamak dakikalar sürebilir. Bu “Fan-out Lag” (Yelpaze Gecikmesi), influencer’ın gönderisinin bazı takipçilere anında, bazılarına ise 10 dakika sonra ulaşmasına neden olur. Daha da kötüsü, bu yoğun işlem diğer normal kullanıcıların gönderilerinin işlenmesini de engelleyerek sistemin tüm akış tazeliğini bozar.
Sentez: Hibrit Savunma Hattı ve “Sessiz Birleştirme”
Hibrit model, Push ve Pull yaklaşımlarının çatışmasından doğan “Sentez"dir. Modern sosyal medya devlerinin (Twitter/X, Facebook, Instagram) kullandığı bu mimari, kullanıcıları takipçi sayılarına göre kategorize ederek her iki dünyanın da avantajlarını kullanır. Bu yapıda, influencer’ların gönderileri (Pull Side), normal kullanıcıların önceden hesaplanmış akışlarıyla (Push Side) okuma anında “sessizce” ve kullanıcıya fark ettirilmeden birleştirilir.
Sessiz Birleştirme Algoritmasının Adımları
Bir izleyici (takipçi) ana sayfasını açtığında, akış birleştirme servisi (Timeline Aggregator) şu operasyonları eşzamanlı olarak yürütür:
- Push Okuması: Kullanıcının Redis’teki hazır ID listesi çekilir. Bu listede takip ettiği normal arkadaşlarının son gönderileri vardır.
- Influencer Belirleme: Sosyal grafik servisine (Graph Service) danışılarak kullanıcının takip ettiği 50k+ takipçili influencer’lar listelenir.
- Pull Sorgulaması: Belirlenen influencer’ların son N gönderisi, merkezi influencer önbelleğinden (Influencer Post Cache) veya ana veri tabanından çekilir.
- Zaman Damgalı Birleştirme (Temporal Merge): Her iki kaynaktan gelen gönderi ID’leri birleştirilir ve Snowflake ID’lerine (veya timestamp’lerine) göre azalan düzende sıralanır.
- Hidrasyon ve Sunum: Sıralanan ilk 50 ID, içerik veri tabanından metin, resim ve video referanslarıyla doldurularak kullanıcıya JSON formatında döner.
Kod
Burada büyük kod yığınları ekleyerek yazıyı uzatmak istemiyorum ama yaptığım sistemi github linki bırakarak sizlerinde localinizde çalıştırmasını sağlayabilirim:
https://github.com/onurozkir/cheap-social-media
Maliyet Analizi
Aşağıda aslında system-design-primer sistemini ideal bir şekilde kurarsak karşılaşacağımız maliyetleri ve bu yazımızdaki maliyetleri karşılaştırabiliriz.
| Bileşen | Twitter Ölçeği (Primer Mimarisi) | Startup Yaklaşımı | Tahmini Tasarruf |
|---|---|---|---|
| İşlem Birimi | Binlerce Microservice Node | 1-2 Güçlü Bare-Metal Sunucu | %95+ |
| Ana Veritabanı | Sharded MySQL + Cassandra | Tekil, Tuned PostgreSQL | %80+ |
| Cache Katmanı | Terabaytlarca RAM (Redis Cluster) | Minimal Redis + Go In-memory | %90+ |
| Medya Depolama | S3 + CloudFront CDN | Yerel NVMe + DigitalOcean Droplet | %85+ |
| Mesaj Kuyruğu | Kafka Cluster | Basit SQS | %90+ |
| Kalem | Bare Metal (RAM Odaklı) | Cloud/Managed DB Yolu |
|---|---|---|
| Aylık Sabit | ~$100 - $300 (Bare Metal + RAM) | $2.000 - $10.000+ (RDS + ElastiCache) |
| Performans | Ultra Düşük Latency (<1ms) | Düşük Latency (1-5ms network dahil) |
| Maliyet Esnekliği | RAM dolarsa yenisini alırsın (Ucuz) | Scale-up yaparsan faturan logaritmik artar |
| Gizli Gider | Ops/Bakım Emeği (Senin zamanın) | Data Egress (Ağ Vergisi) |
Yarın 1 milyon kişi gelirse; ödeyeceğin RAM ücreti, cloud sunucularına ödeyeceğin paranın yanında “sakız parası” kalır. Bare metal’de RAM takip devam etmek, startup’ın hayatta kalma şansını %90 artırır. Elon Musk’ın Twitter’ı cloud’dan çekip kendi sunucularına taşıyarak yılda 100 milyon dolar tasarruf etmesi boşuna değil!
1. RAM Maliyeti: Bare Metal vs. Cloud
Bare metal sunucuda RAM “tek seferlik” bir masraftır. 128 GB RAM’li bir sunucu kiralamak veya mevcut sunucuna RAM takviyesi yapmak startup bütçesi için deve de kulak kalır.
- Bare Metal Yaklaşımı: Bir sunucuya 128 GB RAM takarsın (veya o kapasitede bir sunucu kiralarsın, aylık maliyeti ~$100-200 arası değişir), bu RAM’i son baytına kadar sen yönetirsin.
- Cloud/PaaS Yaklaşımı: AWS’de 128 GB RAM kapasiteli bir
r6i.4xlargeinstance çalıştırmaya kalksan, sadece sunucu ücreti ayda $700-800‘den başlar. Üstelik bu sadece “boş” makine! Üzerine Managed DB (RDS) veya ElastiCache koyarsan fatura ikiye, üçe katlanır.
1 milyon RPS senaryosunda, veriyi RAM’de (Local Cache) tutmak sana bedavaya yakın bir hız sağlar çünkü ağ üzerinden başka servise gitme maliyetin sıfırdır.
2. Veri Transfer Ücretleri
Herkesin gittiği “Cloud” yolunda asıl can yakan şey RAM değil, veri transferidir.
- Cloud Yolu: 1 milyon kullanıcıya her saniye 10’ar post gönderdiğini düşün. Her post (metadata + text) ortalama 1 KB olsa, saniyede 10 GB veri transferi yaparsın. AWS’de 10 TB’dan sonra GB başına $0.05 - $0.09 arası fatura kesilir. Ay sonunda sadece dolar milyarderleri o faturayı ödeyebilir, startup’ı kapatıp geri beyaz yakalı işinize dönersiniz.
3. PostgreSQL ve Redis: IOPS vs. RAM
Herkesin gittiği yolda (Managed DB) sana IOPS (saniyedeki giriş/çıkış işlemi) satarlar. Saniyede 1 milyon istek DB’ye vurduğunda, Amazon sana “Provisioned IOPS” faturasını öyle bir çıkarır ki sülalene borç kalır.
- Bizim Yapımızda (Pod-Local RAM): DB’ye sadece pagination yapan “meraklı” kullanıcı gider. 1 milyon kişinin sadece %10’u scroll yapsa (100k kişi), DB yükün inanılmaz düşer.
- PostgreSQL Optimizasyonu: Bare metal sunucunda
shared_buffersdeğerini RAM’in %40’ına (örneğin 50GB) ayarlarsan, PostgreSQL zaten o pagination datalarını kendi içinde cache’ler. Cloud’da bu performansı almak için servet ödersin.
Pros & Cons
Pros
- DB’yi Kurtarmak: 1 milyon kişinin %80’i genelde sadece ilk sayfaya bakıp çıkar (bounce rate). Onları yerel RAM’den karşılayarak veritabanını ve Redis’i “öldürmekten” kurtarıyorsun.
- Maliyet: Cloud sağlayıcılarına ödeyeceğin “Ağ Transfer” maliyetlerini minimize ediyorsun.
- Hız: İlk giriş “sub-millisecond” seviyesinde olur; kullanıcı uygulamanın uçtuğunu sanır.
Cons
- “Refresh” Kaosu: Kullanıcı sayfayı yenilediğinde (LB onu başka bir Pod’a atarsa) birden tamamen farklı gönderiler görebilir. Bu bir sosyal medya platformu için çok dert değil (keşfet etkisi yaratır), ama reklam yerleşimi yapıyorsan “gösterim” (impression) sayılarını takip etmek zorlaşır.
- Karmaşa: RabbitMQ üzerinden 10 Pod’a farklı farklı datalar basmak karmaşık olabilir.
- “Kişiselleştirme” vs. “Genel Keşfet”: Twitter ve Facebook’un Timeline’ı sadece “en popüler 5 post” değildir. Olay senin takip ettiğin insanların gönderilerini görmendir. Biz burada yankı odası oluşturarak maliyet uğruna bun özelliği reddediyoruz.
- Cache Invalidation: Düşün ki bir “ünlü” yanlışlıkla bir şey paylaştı ve 2 saniye sonra sildi. 10 farklı podun RAM’indeki o datayı anında temizlemek çok zordur. RabbitMQ ile mesaj göndersen bile podlardan biri o an meşgulse post orada kalmaya devam eder.
Ne zaman Kullanırız?
İlk başta dediğim gibi bu yapı aslında en ideal yapı değil. EN düşük bütçe ile sadece mimari farkları ortaya koyarak maliyet azaltımının aslında ne kadar fazla yapılabileceği deneyi. Kurulan bu yapı belki Start-up’ınınız ilk 6 ayında veya ilk yatırımı alana kadar kurabilir ve düşük maliyetlerle hayatınıza devam edebilirsiniz. Bizim yapı, bir startup’ın “Day 1” (ilk gün) savunmasıdır. Saniyede 1 milyon kişi “Keşfet” sayfasına hücum ettiğinde bu zırh bizi korur. Ama Onur “Ben arkadaşlarımı görmek istiyorum” dediği an, mecburen yatırımcıdan para isteyip bir Redis cluster kuracağız.
Kaynaklar
- Design the Twitter timeline and search
- Design a system that scales to millions of users on AWS
- A Complete Guide for System Design Interviews
- How to Design Twitter (X) in a System Design Interview?
- Fanout Exchange and Broadcast Patterns.
- The Architecture Twitter Uses to Deal with 150M Active Users
- Kleppmann, M. (2017). Designing Data-Intensive Applications.
- Redis.io. (2025). Caching Strategies and Invalidation Patterns.
- The Justin Bieber Problem: When Celebrities Break the Internet (and How Engineers Fix It)”