Bu yazıda dağıtık veya monolith sistemlerde olmazsa olmaz dediğimiz, End-to-End mimari tasarımlarda bazen unutulan ama unutmayanların ilk 3’te saydığı, AI sistemlerin ise “bana baştan sonra uygulama yap” promptu girildiğinde AI’nin bile unuttuğu kritik bir konuyu ele alacağız. End-to End Observability ve Monitoring.
Bir zamanlar, profesyonel hayatta Newrelic ve Datadog kullanarak yaptığım Monitoring işlemlerini “Parası az bir start-up” olsa nasıl yapılacağını düşündüm. Çünkü Newrelic’in “yorucu” fiyatlamasını ve sürekli kafasına göre değiştirilen arayüzü çoğu kişiyi de yorabilirdi. Tamamen açık kaynak uygulamalarla tüm uygulamayı izleyecek mimariyi zaman zaman kafamda oluşturdum ve en son yazıya ve koda dökebildim. Hatta bunu profesyonel hayatımda da ufak bir projede kullanabildim. Sıra bildiklerimi anlatmaya geldi. Aşağıda “Ne Nedir?” ile başlayıp bir demo ile bitirmeyi umuyorum. İyi okumalar.
- Observability : Bir uygulamanın iç durumunu dışarıdan topladığı veriler ve metrikler (log, trace, vs) üzerinden anlayabilme yeteneğidir.
- Monitoring : Toplanan bu verileri reel-time izlemesi; anomaliler, uyarılar, alarmlar ve dashboard aracılığıyla sistem sağlığını takip etmesidir.
- End-to-End: Clientten başlayıp veritabanına, altyapıya, 3rd servislere kadar uzanan tüm yol boyunca metrik–log–trace üçlüsünü kesintisiz toplamak ve ilişkilendirmektir.
Ben Burada Neyi Yaptım, Neyi Başardım?
- NET Core Minimal API üzerine OpenTelemetry ile
- HTTP request–response metrikleri
- .NET runtime ve process metrikleri
- PostgreSQL query ve bağlantı metrikleri
- OpenTelemetry’i metrik tercümanı (burası çokomelli)
- Prometheus’u metrik toplama motoru,
- Alertmanager’ı alert mekanizması,
- Grafana’yı; dasboard, SLO göstergeleri ve “Alert list” ile görselleştirme,
- Jaeger ile dağıtık trace toplama,
- Loki + Promtail ile konteyner log’larının toplanması ve trace-log korelasyonu
amaçladım. Böylece API’den veritabanına, container katmanına kadar end-to-end olarak “wtf? ne oluyor?” sorusuna yanıt veren bir sistem kurdum.
Hedefler ve Kapsamı
- Hedefler
- Uygulama performansını ve hatalarını gerçek zamanlı izlemek
- bottleneck noktaları hızlıca tespit etmek
- Alert ve SLO’lar tanımlayarak süreklilik kazanma
- Kapsam
- .NET metrik → HTTP, runtime, GC
- PostgreSQL Metrikler → postgres-export
- Dağıtık trace → Jaeger
- Log yönetimi → Loki
- Container izleme → hostmetrics
- Alert → Prometheus Alertmanager
Hangi Boşlukları Kapattım?
| Eksik | Çözüm |
|---|---|
| “Neler oluyor?” | Metrics + Trace + Logs |
| Errors | Gerçek zamanlı Alerting |
| Performans analizi | Uçtan uca SLO ve panolar |
| Debugging | Trace-Log korelasyonu ile root-cause analizi |
| Altyapı izleme | Host metrikleri |
| DB review | Database CPU Host metrikleri |
Tammammdır.. Buraya kadar hem kod, hem de altyapıda “observability” olduk gibi, İlk request’ten son next() konumuna kadar içerde dolaştığı tüm evreleri hem izledik hem de raporluyoruz.
Neler Kullandım?
OpenTelemetry Collector: Yukarıda çokomelli diye bahsettiğim yer burası. OTel, metrik, trace ve log verilerini toplamak, dönüştürmek, yönlendirmek üzere çalışan bir agenttır. Aslında herkesin anlayacağı bir şekilde OTel bir tercümandır. Eline çevrede gördüğü olayları kendince kağıda döken ve bu verileri anlayana anladığı gibi anlatan bir uygulamadır. Tam burada bir felsefi soru soralım: “Hastaneden aldığın reçete üzerindeki yazı doktor yazdığı için doktor yazısı mıdır? Yoksa bu yazıyı sadece eczaneci anladığı için eczaneci yazısı mıdır? Yoksa bunu OTel çevirdiği için yazı onun mudur?” OpenTelemetry projesi Google, Microsoft, Lightstep ve CNCF üyesi şirketlerin katkılarıyla 2019’da başlatıldı. Uygulamalardan gelen OTLP verilerini merkeziye toplamak ve işleyip Prometheus’a, Jaeger’a veya başka veri saklama depolarına gönderir.
- OTel, temel olarak stateless bir agent olarak çalışmakta. Gelen verileri (traces, metrics, logs) önce memory-backed bir queue’da tutar. Ardından konfigürasyondaki exporter’lara iletir. Varsayılan kurulumda disk veya uzun süreli saklama yoktur.
GitHub - open-telemetry/opentelemetry-collector: OpenTelemetry Collector
Prometheus: time-series veritabanı (TSDB) ve pull-tabanlı metrik toplama/kaydetme sistemi. İlk prototipi 2012’de SoundCloud’da geliştirildi, Uygulamada
AddPrometheusExporter()ile/metricsendpoint’i açılır.app.MapPrometheusScrapingEndpoint()ile Kestrel üzerinden metrikler scrape edilmeye hazır hâle gelir.- Disk üzerinde TSDB (Time Series Database) olarak saklar. Default dizin
--storage.tsdb.pathile./data/’dır; içinde WAL (Write-Ahead Log) ve 2 saatlik bloklar olarak veri tutulur. - Metrik saklama sınırları belirlenebilir.
--storage.tsdb.retention.time=15dveya--storage.tsdb.retention.size=50GB - Temel metrik tipleri (Prometheus 4 tip destekler):
- Counter: Monoton artan sayaç
- Gauge: İstediği yönde artıp azalabilen değer
- Histogram: Gözlemleri bucket’lara ayırır;
_bucket,_sum,_countserileri - Summary: İstemci tarafında hesaplanan quantile değerleri
- Api’de açılan
/metricsuzantılı bir url üzerinden metrikleri toplamakta.
- Disk üzerinde TSDB (Time Series Database) olarak saklar. Default dizin
Grafana: Dashboard ve alerting platformu. Prometheus, Loki, Jaeger ve daha pek çok veri kaynağını tek bir arayüzde birleştirme için kullanıldı. Grafana’da Prometheus data source’u eklenir; uygulamanın
/metricsendpoint’i dashboard’larda görselleştirilir.Loki: log verisi toplayan, endeksleyen ve sorgulamanı sağlayan bir log aggregation systemdir. Promtail ile beraber
journalctl,docker,syslog,fileskaynaklardan logları toplar, etiketler ve Loki’ye yollar. Aksi belirtilmediği sürece logları filesystem üzerinde biriktirir. istenilendepolama sunucuna da kaydedilebilir.- Loki tabanlı bir log stack 3 bileşenden oluşur:
- Promtail, günlükleri toplamaktan, taglamaktan ve Loki’ye göndermekten sorumlu.
- Loki, günlükleri toplamak ve sorguları işlemekten sorumlu ana hizmettir.
- Günlükleri sorgulamak ve görüntülemek için Grafana.
- Loki tabanlı bir log stack 3 bileşenden oluşur:
Jaeger: Dağıtık trace toplama ve görselleştirme sistemi.Uber’ün 2015’te açık kaynak olarak yayınladığı bir proje. Mikroservis çağrı zincirini uçtan uca görme, latency ve hata analizleri.
- Agent veya Collector bileşenlerine gRPC/HTTP (OTLP) protokolleriyle gönderilir.
- Uygulamada OpenTelemetry SDK kullanılarak
AddOtlpExporter()ile doğrudan OTLP formatında çıkar. - Jaeger Agent, uygulamalarla aynı host/namespace’te run edip UDP’yi proxy’ler; Collector ise gRPC/HTTP üzerinden sinyalleri kabul eder
- Verileri Elastic gibi dağıtık sistemlerde depolayabilir. Aksi belirtilmediği sürece in-memory çalışır.
- Uygulama içinde OpenTelemetry SDK’ları (
Instrumentation.*) ile tracer oluşturulur. - Collector/Agent başına birkaç bin span/saniye; sharding ve horizontal pod autoscaling ile yatay ölçek sağlanır.
Aşağıda ise kafamızda kurduğumuz yapının şeması var:
Kodlama
Peki kodlamaya geçelim. gerçi en son github reposunu vereceğim ancak buradan da açıklayarak gidelim.
Program.cs
using System.Diagnostics;
using Microsoft.AspNetCore.Mvc;
using Microsoft.EntityFrameworkCore;
using Npgsql;
using OpenTelemetry.Resources;
using OpenTelemetry.Trace;
using OpenTelemetry.Metrics;
using OtelTraceMetricsDemo;
var builder = WebApplication.CreateBuilder(args);
// JSON Console Logger (TraceId/SpanId dahil)
builder.Logging.ClearProviders();
builder.Logging.AddJsonConsole(options =>
{
options.IncludeScopes = true;
options.JsonWriterOptions =
new System.Text.Json.JsonWriterOptions { Indented = false };
});
// PostgreSQL config
builder.Services.AddDbContext<AppDb>(opt =>
opt.UseNpgsql(builder.Configuration.GetConnectionString("Pg")));
// OpenTelemetry Kurulumu
builder.Services.AddOpenTelemetry()
.ConfigureResource(r => r.AddService("otel-trace-metrics-api")) // unique bir isim
.WithTracing(t => t
.AddAspNetCoreInstrumentation() // Request traces
.AddHttpClientInstrumentation() // Response traces
.AddNpgsql() // PostgreSQL trace
.AddSource("Logic") // Business/logic log
.AddOtlpExporter(opt => // OTLP (gRPC/HTTP) aracılığıyla Collector’a gönder
{
opt.Endpoint = new Uri("http://otel-collector:4317");
}))
// Metrics (metrik) pipeline
.WithMetrics(m => m
.AddAspNetCoreInstrumentation() // HTTP metrikleri (request sayısı, latency)
.AddHttpClientInstrumentation() // Client metrikleri
.AddProcessInstrumentation() // Process CPU/memory metrikleri
.AddRuntimeInstrumentation() // .NET runtime (GC, heap, threads)
.AddMeter("Npgsql") // PostgreSQL metric
.AddPrometheusExporter()); // /metrics endpoint’i açarak Prometheus’a expose et
// Yukarıdaki property'lerin hepsini kullanabilmek için NuGet paketlerini implement etmek gerekli.
var app = builder.Build();
var logic = new ActivitySource("Logic");
// Configure the HTTP request pipeline.
if (app.Environment.IsDevelopment())
{
app.UseSwagger();
app.UseSwaggerUI();
}
using (var scope = app.Services.CreateScope())
{
var db = scope.ServiceProvider.GetRequiredService<AppDb>();
await db.Database.MigrateAsync(); // tablo ve şema otomatik oluşur
}
// Prometheus Scrape Endpoint’ini Haritalama
// /metrics yolunu açar, Prometheus buradan metrik çeker
app.MapPrometheusScrapingEndpoint();
app.UseHttpsRedirection();
app.MapGet("/todos", async ([FromServices] AppDb db) =>
{
using var _ = logic.StartActivity("logic:list");
return await db.Todos.AsNoTracking().ToListAsync();
});
app.MapPost("/todos", async (
[FromBody] Todo todo,
[FromServices] AppDb db) =>
{
using var _ = logic.StartActivity("logic:create");
db.Add(todo);
await db.SaveChangesAsync();
return Results.Created($"/todos/{todo.Id}", todo);
});
app.MapGet("/invalid", async () =>
{
using var _ = logic.StartActivity("logic:invalid");
return Results.Problem(detail: "Bu bir test 500 hatasıdır.", statusCode: 500);
});
app.MapPost("/deadlock", async ([FromServices] IConfiguration config) =>
{
var connStr = "Host=postgres;Port=5432;Username=demo;Password=demo;Database=todo;Pooling=true;Minimum Pool Size=0;Maximum Pool Size=20";
using var conn1 = new NpgsqlConnection(connStr);
using var conn2 = new NpgsqlConnection(connStr);
await conn1.OpenAsync();
await conn2.OpenAsync();
using var tx1 = await conn1.BeginTransactionAsync();
using var tx2 = await conn2.BeginTransactionAsync();
try
{
// lock id = 1 row
var cmd1 = new NpgsqlCommand("UPDATE \"Todos\" SET \"Done\" = true WHERE \"Id\" = 1;", conn1, tx1);
await cmd1.ExecuteNonQueryAsync();
// lock id = 2 row
var cmd2 = new NpgsqlCommand("UPDATE \"Todos\" SET \"Done\" = false WHERE \"Id\" = 2;", conn2, tx2);
await cmd2.ExecuteNonQueryAsync();
// deadlock 1
var task1 = Task.Run(async () =>
{
var cmd = new NpgsqlCommand("UPDATE \"Todos\" SET \"Done\" = true WHERE \"Id\" = 2;", conn1, tx1);
await cmd.ExecuteNonQueryAsync();
});
// deadlock 2
var task2 = Task.Run(async () =>
{
var cmd = new NpgsqlCommand("UPDATE \"Todos\" SET \"Done\" = false WHERE \"Id\" = 1;", conn2, tx2);
await cmd.ExecuteNonQueryAsync();
});
await Task.WhenAll(task1, task2); // lock
}
catch (Exception ex)
{
Results.Problem(detail: $"Deadlock exception: {ex.Message}", statusCode: 500);
}
return Results.Ok("Deadlock dashboard");
});
app.Run();
docker-compose.yml
- Uygulamamız dockeri le ayağa kalkacak tüm paketler ve conf bilgileri burada girilecek
version: "3.9"
services:
api:
build:
context: .
dockerfile: src/OtelTraceMetricsDemo/Dockerfile
environment:
- CONNECTIONSTRINGS__PG= Host=postgres;Port=5432;Username=demo;Password=demo;Database=todo;Pooling=true;Minimum Pool Size=0;Maximum Pool Size=20
- OTEL_EXPORTER_OTLP_ENDPOINT=http://otel-collector:4317
- ASPNETCORE_URLS=http://+:8080
depends_on: [postgres, otel-collector]
ports: ["8080:8080"]
postgres:
image: postgres:16
container_name: todoDB
restart: always
ports:
- "62355:5432"
environment:
POSTGRES_USER: demo
POSTGRES_PASSWORD: demo
POSTGRES_DB: todo
volumes:
- pgdata:/var/lib/postgresql/data
otel-collector:
container_name: otelCollector
image: otel/opentelemetry-collector-contrib:0.87.0
command: ["--config=/etc/otel-collector.yaml"]
volumes: ["./otel-collector.yaml:/etc/otel-collector.yaml:ro"]
ports:
- "4317:4317" # OTLP gRPC
- "8889:8889" # Prometheus
environment:
# abi sen beni niye lokiye jeagera mecbur tutuyorsun ben belki elastic, newrelic kullanıyorum
# diyecekler için farklı log mekanizmaları burada tanımlayıp
# metrikleri iletebiliriz. Böyle belki ilerde kendi newrelic'imizi yazarız
# Hedef seçimi (logs için): loki | newrelic | kibana
- EXPORT_TARGET=${EXPORT_TARGET:-loki}
# New Relic (OTLP/HTTP)
- NR_OTLP_ENDPOINT=${NR_OTLP_ENDPOINT:-https://otlp.nr-data.net}
- NR_LICENSE_KEY=${NR_LICENSE_KEY:-}
- EXPORT_TARGET=${EXPORT_TARGET:-elastic} # elastic | loki | datadog | newrelic | splunk
# Elastic APM OTLP endpoint:
# - Elastic Cloud: https://kibana.apm.tr.elastic-cloud.com
- ELASTIC_OTLP_ENDPOINT=${ELASTIC_OTLP_ENDPOINT:-http://apm-server:8200}
# Authorization header DEĞERİ (ikiden biri):
# Authorization: Bearer <secret_token>
# Authorization: ApiKey <api_key>
- ELASTIC_AUTH_HEADER=${ELASTIC_AUTH_HEADER:-Authorization=Bearer your_secret_token}
jaeger:
container_name: jaeger
image: jaegertracing/all-in-one:1.57
ports:
- "16686:16686" # Jaeger UI (trace görüntüleme)
- "14250:14250" # Jaeger gRPC Collector endpoint
grafana:
container_name: grafana
image: grafana/grafana:10.4.2
depends_on: [otel-collector]
ports: ["3000:3000"] # Grafana UI
prometheus:
image: prom/prometheus:v2.45.0
container_name: prometheus
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml:ro
- ./otel_compat_rules.yml:/etc/prometheus/otel_compat_rules.yml:ro # OTEL compat kuralları
- ./alert-rules.yml:/etc/prometheus/alert-rules.yml:ro # Alert kuralları
ports:
- "9090:9090"
depends_on: [ otel-collector ]
# Postgres iç ölçümleri (cache hit, bgwriter, locks…) istiyorsan:
postgres-exporter:
container_name: postgresExporter
image: quay.io/prometheuscommunity/postgres-exporter:v0.15.0
environment:
DATA_SOURCE_NAME: "postgresql://demo:demo@postgres:5432/todo?sslmode=disable"
depends_on: [ postgres ]
ports:
- "9187:9187"
loki:
container_name: loki
image: grafana/loki:2.8.2
command: -config.file=/etc/loki/local-config.yaml
ports:
- "3100:3100" # Loki HTTP API (query, push)
- "9095:9095" # Loki gRPC
volumes:
- ./loki-config.yaml:/etc/loki/local-config.yaml
- loki-data:/loki
promtail:
container_name: promtail
image: grafana/promtail:2.8.2
volumes:
- /var/log:/var/log:ro
- /var/lib/docker/containers:/var/lib/docker/containers:ro
- ./promtail-config.yaml:/etc/promtail/promtail.yaml:ro
command: -config.file=/etc/promtail/promtail.yaml
alertmanager:
container_name: alertmanager
image: prom/alertmanager:v0.25.0
ports:
- "9093:9093"
volumes:
- ./alertmanager-config.yaml:/etc/alertmanager/config.yml:ro
node-exporter:
container_name: nodeExporter
image: prom/node-exporter:latest
network_mode: host
pid: host
volumes:
- /:/rootfs:ro
- /sys:/rootfs/sys:ro
- /proc:/rootfs/proc:ro
command:
- --path.rootfs=/rootfs
volumes:
pgdata:
driver: local
loki-data:
otel-collector.yaml
- Şimdi başlayalım. İlk önce çok bahsettiğimiz OTel Collector yapılandırılması:
# Görüldüğü üzere yapılandırma 3 ana bölümden oluşuyor
# receivers, hangi metriklerin toplayacağını belirtir.
# processors, toplanan verileri ne yapacağı?
# exporters, metrikleri hangi kanallara göndereceği, Tercüman özelliği
receivers:
otlp:
protocols:
grpc: # 4317
http: # 4318, AddOtlpExporter() ile metrikler bu porta gönderilir.
hostmetrics: # cpu metrik
collection_interval: 10s # 10 saniyede bir scrape et
scrapers: #neleri scrape edelim
cpu: { }
memory: { }
filesystem: { } # dosya sistemi kullanım oranları
network: { } #network trafik
disk: { } # Disk I/O istatistikleri
load : { } # system load averages
paging : { } # Swap/disk paging
processors: #
batch: {}
resource:
# docker-compose'da bahsettiğim ben farklı yere atacağım
# derseniz burada ekstra bir yapılandırma gerekli
attributes:
- action: upsert
key: export.target
value: ${EXPORT_TARGET}
routing:
attribute_source: resource
from_attribute: export.target
table:
- value: jaeger
exporters: [ otlp/jaeger ]
- value: elastic
exporters: [ otlphttp/elastic ]
- value: loki
exporters: [ otlphttp/loki ]
- value: newrelic
exporters: [ otlphttp/newrelic ]
exporters:
prometheus:
endpoint: "0.0.0.0:8889" # Prometheus otelden 8889 portunu scrape ederek metrikleri alacak.
# Logs → Jaeger (OTLP/HTTP)
otlp/jaeger:
endpoint: jaeger:4317
tls:
insecure: true
# Logs → Loki (OTLP/HTTP)
otlphttp/loki:
endpoint: http://loki:3100/otlp
# Logs → New Relic (OTLP/HTTP)
otlphttp/newrelic:
endpoint: ${NR_OTLP_ENDPOINT}
headers:
api-key: ${NR_LICENSE_KEY}
# Logs → Elastic (OTLP/HTTP)
otlphttp/elastic:
endpoint: ${ELASTIC_OTLP_ENDPOINT}
headers:
${ELASTIC_AUTH_HEADER} # örn: Authorization=ApiKey abcd123...
# Elastic Cloud için TLS zaten zorunlu; self-managed için http de olur
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch]
exporters: [otlp/jaeger]
metrics:
receivers: [otlp, hostmetrics]
processors: [batch]
exporters: [prometheus] # metrics’i Prometheus’a da veriyoruz; istersen routing ile elastic’e de akıtırsın
prometheus.yml
- Prometheus, tüm metrikleri toplar. OTel, Prometheus ile anladığı dilden konuşur.
global:
scrape_interval: 15s # Tüm scrape joblarının refresh aralığı
rule_files:
- 'otel_compat_rules.yml' # otel rulesi aşağıda bir yerlerde yazıldı
- 'alert-rules.yml' # custom alert rules, alertmanager için
alerting:
alertmanagers:
- static_configs:
- targets: ['alertmanager:9093'] # Prometheus’un alertleri buraya gönder
# scrape edilecek joblar
scrape_configs:
- job_name: 'otel-collector'
static_configs:
- targets: ['otel-collector:8889'] # OTel'in topladığı metrikler
- job_name: 'postgres-exporter' # PostgreSQL exporterdan expose edilen metrikler
static_configs: [{ targets: ['postgres-exporter:9187'] }]
- job_name: 'api' # .NET Core /metrics endpoint’i
metrics_path: /metrics
static_configs: [ { targets: [ 'api:8080' ] } ]
- job_name: 'node' # Host metrikc 9100 portu
static_configs:
- targets: [ 'node-exporter:9100' ]
otel_compat_rules.yml
- Bir nevi name convertor olarak düşünebiliriz. “postgres_up” metriğini, “pg_up” olarak adlandırıyor. Search anında “ben böyle arayacağım” dediğimiz metrikler için genişletilebilir.
groups:
- name: otel_compat
rules:
- record: http_request_duration_seconds_count
expr: http_server_duration_count
- record: http_request_duration_seconds_sum
expr: http_server_duration_sum
- record: http_requests_total
expr: http_server_request_count
- record: postgres_up
expr: pg_up
- record: postgres_database_size_bytes
expr: pg_database_size_bytes{datname="$datname"}
alert-rules.yml:
- Prometheus, “ben metrikleri topluyorumda ne yapacağım bunları alarm falan mı vereceğim?” diye sorarsa evet bu şartları görürsen alarm ver yapılandırmalarımız.
groups:
- name: api-and-db-alerts
rules:
- alert: ApiHighErrorRate
expr: rate(http_server_request_duration_seconds_sum{http_response_status_code=~"5.."}[5m]) > 0
for: 0 # Bu durum en az 1 dakika sürerse uyarıyı gönder
labels:
severity: warning
annotations:
summary: "API'de hata oranı %1’i aştı (son 5dk)"
- alert: PostgresDown
expr: pg_up == 0 # hatırlarsanız otel_compat_rules.yml dosyasında bu ismi değiştirmiştik
for: 0
labels:
severity: critical
annotations:
summary: "PostgreSQL Exporter pg_up=0 raporladı"
- alert: PostgresDeadlockDetected
expr: increase(pg_stat_database_deadlocks[5m]) > 0
for: 0
labels:
severity: warning
annotations:
summary: "PostgreSQL üzerinde son 5 dakikada deadlock oluştu"
description: "Deadlock oluştu. İlgili trace için: "
alertmanager-config.yaml
- “E tamam vereyim alarmı da nasıl kime vereyim” sorusunun cevabı ise burada
global:
resolve_timeout: 5m
route:
group_by: ['alertname']
receiver: 'msteams'
group_wait: 30s # İlk uyarıyı göndermeden önce bekleyeceği süre
group_interval: 5m # Aynı grup içinde sonraki uyarılar arasındaki minimum zaman aralığı
repeat_interval: 4h # Aynı uyarıyı tekrar tekrar göndermeden önceki süre
receivers: # hangi kanala göndereceği, telegram/msteam/slack bir çok kanal kullanılabilir.
- name: 'msteams'
webhook_configs:
- send_resolved: true
# MS Teams kanalı Incoming Webhook URL’i
url: "https://outlook.office.com/webhook/YOUR_WEBHOOK_URL"
message: |
**Alert:** {{ .CommonLabels.alertname }}
**Severity:** {{ .CommonLabels.severity }}
**Instance:** {{ .CommonLabels.instance }}
**Summary:** {{ .CommonAnnotations.summary }}
**Details:**
{{ range .Alerts -}}
• *{{ .Labels.alertname }}* on *{{ .Labels.instance }}*: {{ .Annotations.description }}
{{ end }}
inhibit_rules: # Bir alert’in başka bir alert’i bastırma (inhibit) kuralı
- source_match:
severity: 'warning'
target_match:
severity: 'warning'
equal: ['alertname', 'job']
loki-config.yaml
- Logları (sys, docker, kube, journal vs) da OTel’e göndermek için
auth_enabled: false # Authentication
server:
http_listen_port: 3100 # HTTP API portu
grpc_listen_port: 9095 # gRPC API portu
common:
# in-memory ring is fine for single-instance
path_prefix: /loki
replication_factor: 1
ring:
kvstore:
store: inmemory
storage_config:
boltdb_shipper:
active_index_directory: /loki/index # Index dosya dizini
cache_location: /loki/boltdb-cache # Index sorguları için local cache
filesystem:
# where to keep the log chunks themselves
directory: /loki/chunks`
schema_config:
configs:
- from: 2025-05-07 # Bu tarihten itibaren bu şema ve depolama kullanılsın
store: boltdb-shipper
object_store: filesystem
schema: v12
index:
prefix: index_
period: 24h
ingester:
lifecycler:
ring:
kvstore:
store: inmemory
limits_config:
enforce_metric_name: false # Metric adı validasyonu
promtail-config.yaml
- Lokinin log iletebilmesi için lokiye yardımcı log toplayan sistem
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml
clients:
- url: http://loki:3100/loki/api/v1/push # logları lokiye' gönderir.
scrape_configs:
- job_name: docker-logs
pipeline_stages:
- json: # logların formatı
expressions:
timestamp: time
level: LogLevel
message: Message
trace_id: Scopes[0].TraceId
span_id: Scopes[0].SpanId
- timestamp: # En son prometheus bunlari alacağı için time-series yapılandırılması doğru olmalı
source: timestamp
format: RFC3339Nano
- output:
source: message
static_configs:
- targets: [ localhost ]
labels:
job: docker
app: otel-api
__path__: /var/lib/docker/containers/*/*.log
Şimdiye Kadar Ne Yaptık?
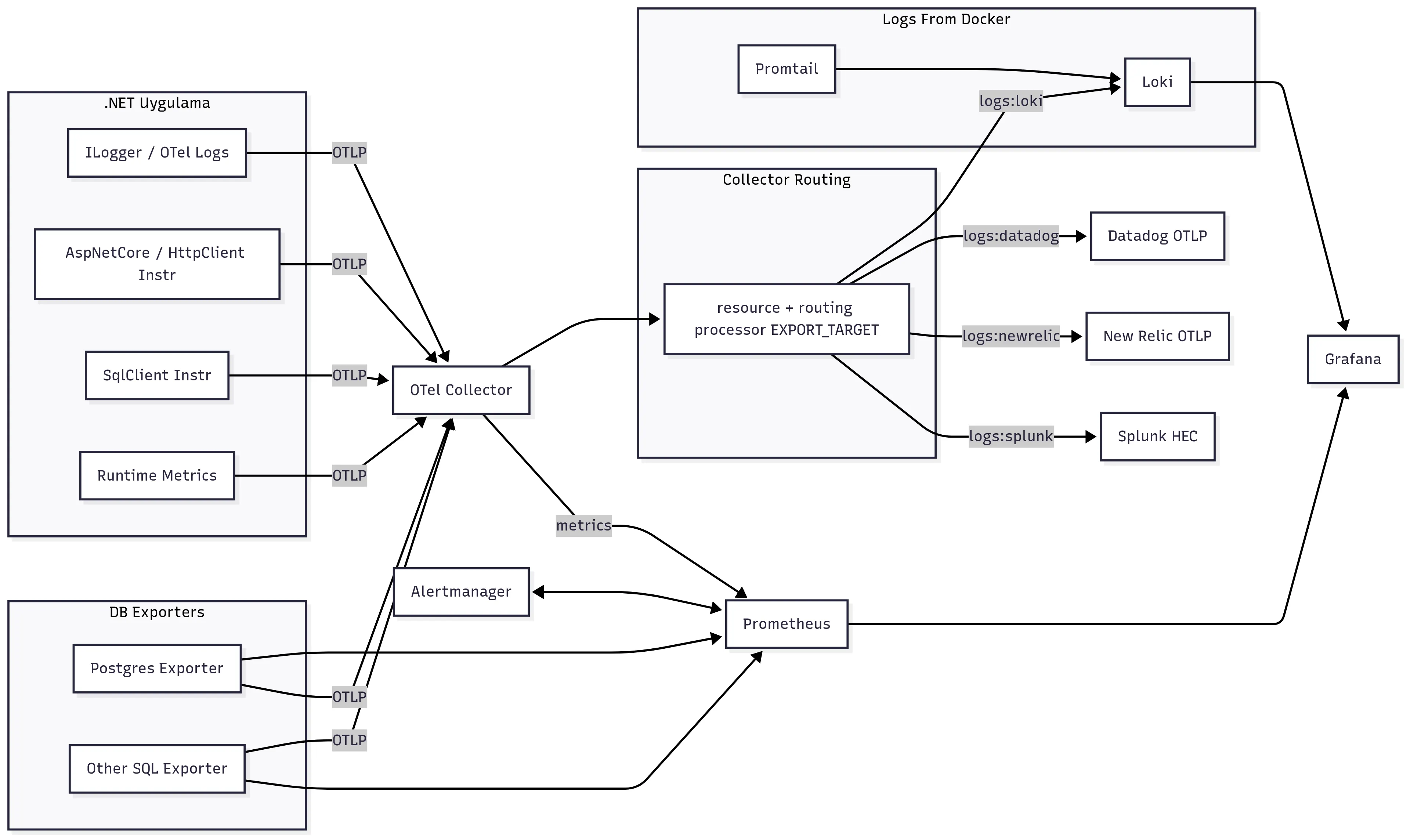
Aslında yukarıdaki şema açıklayıcı ama tekrar edelim
1. - Console/Crashh Logları, Runtime Logları, SqlClient Logları, Http Req/Res Logları - SQL Logları ve Metrikleri - File, JournalCTS, sys log, docker ve kube logların
hepsini OTLP ile OTel Collector’a gönderiyoruz.
- Prometheus, 15s de bir scrap ederek OTel Collector’den metrikleri topluyor.
- Prometheus, aldığı bu verileri önce Alertmanager’dan geçirerek bir alarm durumu varmı kontrolü yapıyor
- Ardından eldeki tüm verileri Dashboard oluşturabilmek için Grafana tarafından veri deposu olarka kullanılıyor.
- OTel aynı anda Routing ile elde tuttuğu dataları farklı log warehouse’lara yolluyor.
Akış aynen bu şekilde.
New Relic ile Karşılaştırma
Peki biz nihayetinde tamamen ücretsiz, açık kaynaklı bir newrelic yaptık. Bunun ücretli verionu ile farkları nelerdir? Burda bu işlerin en önde gelen ürünü Newrelic ile kıyaslayacağız.
| Özellik | New Relic (SaaS) | Açık Kaynak (Prom/Graf/OTel) |
|---|---|---|
| Maliyet | Kullanıcı/host başına artan lisans ücreti | Sıfır lisans maliyeti; altyapı maliyeti |
| Kurulum & Yönetim | Minimum konfigürasyon, ama “kapalı kutu” | Başlangıçta daha fazla konfigürasyon; sonrasında tam kontrol |
| Özelleştirme | API’ler aracılığıyla kısıtlı özelleştirme | Kod, config, plugin ile sınırsız özelleştirme |
| Veri Saklama | New Relic’in saklama politikalarına bağlı; uzun dönem veri ücretli | kendi belirlediğimiz ve local saklama kuralları |
| Vendor Lock-In | Yüksek; verileri çıkarmak karmaşık | Düşük; veri kendi storagemızda (OTLP) |
| Desteklenen Signal’ler | Metrics, traces, logs | Metrics, traces, logs |
Tamamen açık, tek bir protokol (OTLP) kullanarak metrik–trace–log’u birleştiriyor, altyapı üzerindeki full-stack görünürlüğü size veriyor ve büyük SaaS bütçeleri gerektirmiyor.
İleri geliştirme maddeleri
1- Continuous Profiling
– Neden? CPU/Memory leak’leri kod seviyesinde tespit etmek için.
2-Real-User Monitoring (RUM) veya Synthetic Probing
– Neden? end user deneyimini, page loadsürelerini görmek veya dışarıdan periyodik health check yapmak için.
3-Business Metrikler
– Neden? Uygulamanın business’ına dair KPI’ları metrikleştirmek için.
4- Anomaly Detection & Forecasting
– Neden? Manuel threshold yazmak yerine otomatik AI anomali algılamak için.
Kaynaklar
OpenTelemetry Collector Deep Dive
Building decoupled monitoring with OpenTelemetry
host package - go.opentelemetry.io/contrib/instrumentation/host - Go Packages
Configuration | Grafana Loki documentation
Configure Promtail | Grafana Loki documentation
Learn How to Use and Deploy Jaeger Components in Production
Modifying Grafana Opentelemetry Hostmetrics Variable